Predict the future semantci masks of moving objects.
Problem Context
Video prediction is considered to be a more challenging task than language prediction. Given the previous frames of a video, the challenge lies in how a program can predict what will happen next. The difficulty further increases when combining prediction with semantic segmentation, as the system needs to both predict the future and segment semantic objects from the future scene. In this project, we were provided with 22 consecutive frames of images, and the task was to predict the semantic masks for all 22 frames using only the first 11 frames. During the course, we attempted to use two separate models: UNnet for semantic segmentation and SimVP for video prediction. This project is currently ongoing, and we are exploring the potential of using Vector Quantized Variational AutoEncoder (VQVAE) for video representation pre-training and semantic prediction fine-tuning.
Implementation
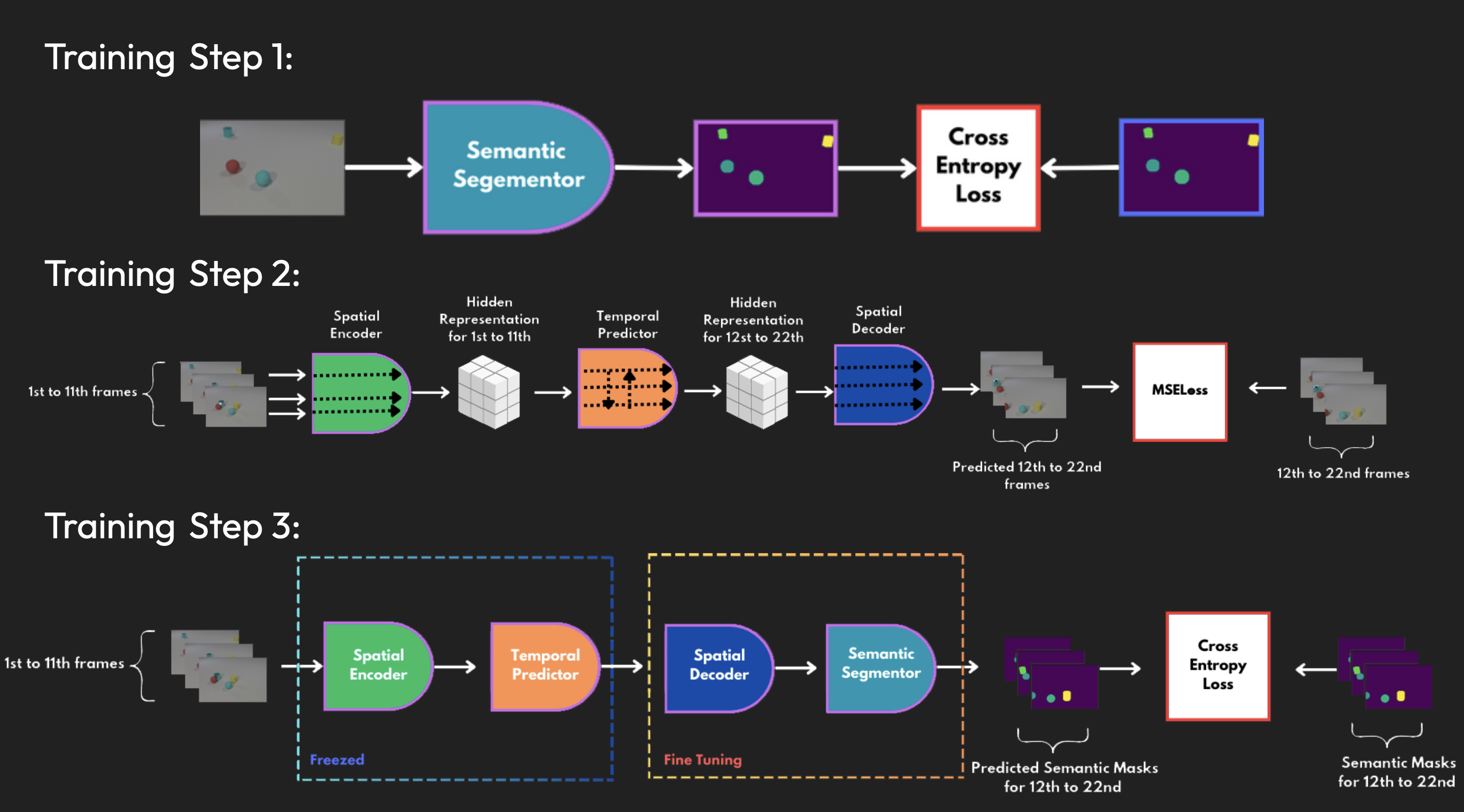
The training scheme of the initial attempt is shown below. First, we used a UNet for semantic segmentation training with cross-entropy loss. Second, SimVP, which is a structure consisting of a spatial encoder, temporal prediction, and spatial decoder, was employed to predict the pixel-level future. Finally, we combined the two models mentioned above and fine-tuned the spatial decoder with semantic segmentation while freezing the first two parts.
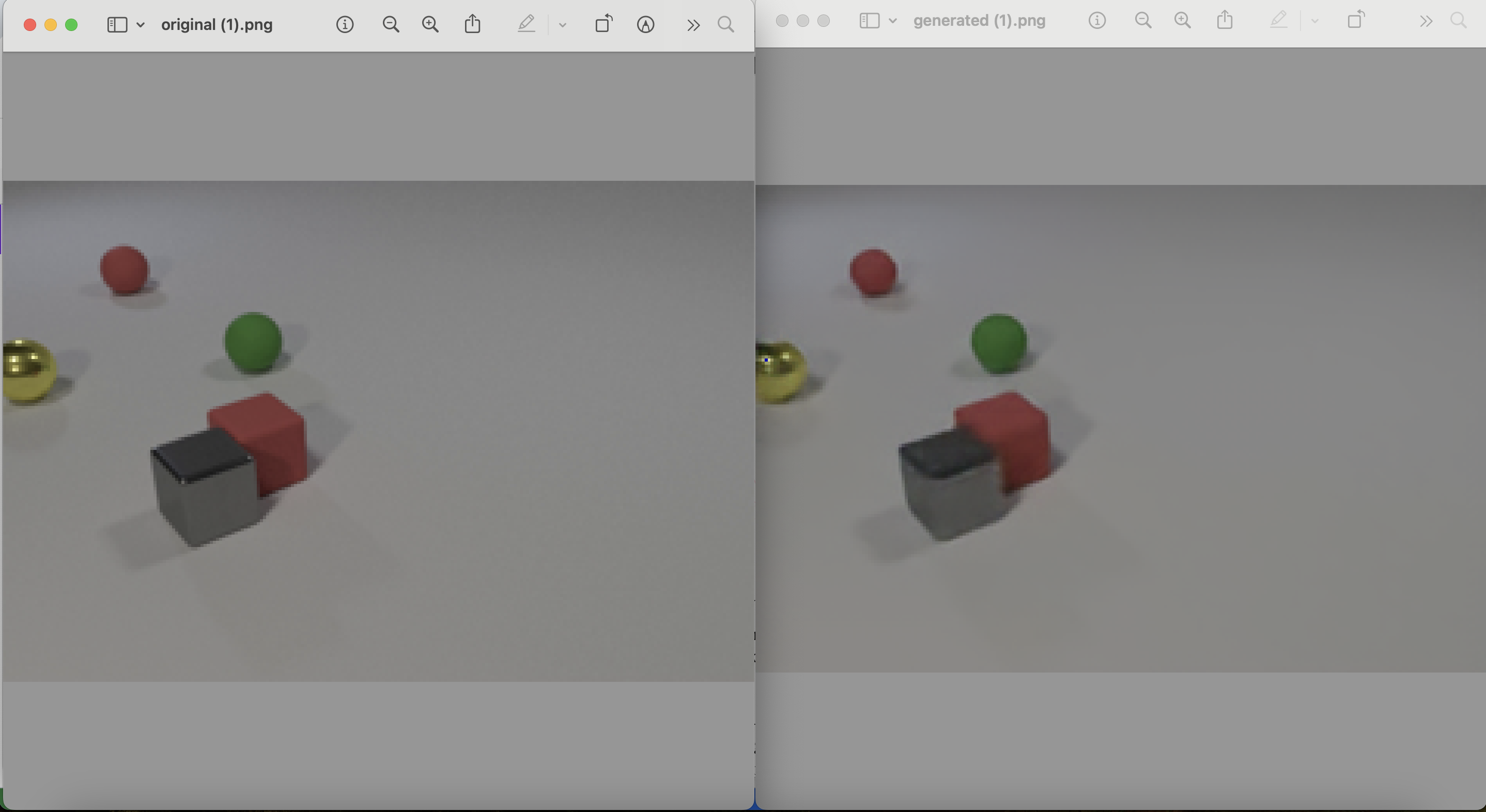
Results
Visualized results are shown below. The predicted images became blurred for the more distant future, leading to less accurate semantic mask results. It turned out that dividing the task into two steps—first predicting the pixels and then segmenting the predicted pixels—might not be a good idea. Instead, it makes more sense to convert the pixel images to a latent representation and then predict the latent representation, which led to the second idea of VQ-VAE pre-training.The first step of the VQ-VAE method is to generate the image using an autoencoder architecture. The encoder converts the images into a latent embedding, the quantizer maps the output embedding to the nearest embedding in its (trainable) codebook, and finally, the nearest embedding is forwarded into the decoder to reconstruct the original images. The mean squared error between the reconstructed and original images is used to optimize the VQ-VAE model. Sample images generated were shown below. Once we have obtained a good embedding encoder, we can use it for video prediction and semantic segmentation in the next step.