Autonomous Surface Vehicle Controller
Problem Context
Consider an Autonomous Surface Vehicle (ASV), a specific type of robot with four thrusters mounted on its underside. The goal is to develop a program that determines the force and direction of each thruster based on the vehicle's current state and its environment. One prevalent approach is to use a deep neural network controller, which can be viewed as a non-linear function that maps each state to an action space. Gradient Descent and Backpropagation are widely used techniques for optimizing the network. However, alternative approaches, such as Evolutionary Algorithms, attempt to find the optimal solution by explicitly searching the model parameter space.

Implementation
The experiment was conducted in a simulated environment called ASVLite, which simulates the dynamics of a vehicle under random ocean surface conditions, particularly various wave forces. To investigate the performance of Evolutionary Algorithms on neural network controller learning, I used libraries such as sferes2, limbo, and map-elites (deprecated). The full project code is available in the ASV-Adaption repository. The project was primarily built using C++, and the main tasks involved defining the objectives and utilizing the algorithm libraries to search for optimal solutions. In each iteration of the genetic search, multiple parameter settings were used to obtain fitness scores, which evaluated the performance of the controller. The settings with higher fitness scores were then selected for the next iteration, undergoing random transformations that mimicked genetic mutations in nature.
Another part of the project is to use deep reinforcement learning, e.g. DDPG to learn the vehicle controller. Under this method, the control problem will be modeled as Markov Decision Process and Actor-Critic models were the primariy function approximator which will be optimized during the learning process. Different from evolutionary algorith, here gradient descent were the optmizer which will chain rule to adjsut controller in the direction that minimize the loss function. The source code could be found on ASV-DeepRL. A major difficulty in this implementation is how to conenct the python tensorflow library to the C++ simulator library. I brideged the gap by temprarily storing the results into file which then would be read by the other library written in a different langugae. Another aspect of the project involved using deep reinforcement learning, such as the Deep Deterministic Policy Gradient (DDPG) algorithm, to train the vehicle controller. In this approach, the control problem is modeled as a Markov Decision Process, and Actor-Critic models serve as the primary function approximators, which are optimized during the learning process. Unlike evolutionary algorithms, gradient descent is used as the optimizer in this case. It employs the chain rule to adjust the controller in the direction that minimizes the loss function. The source code for this part of the project can be found in the ASV-DeepRL repository. One significant challenge in this implementation was figuring out how to connect the Python TensorFlow library with the C++ simulator library. To bridge this gap, I temporarily stored the results in files, which were then read by the other library written in a different language.
Results
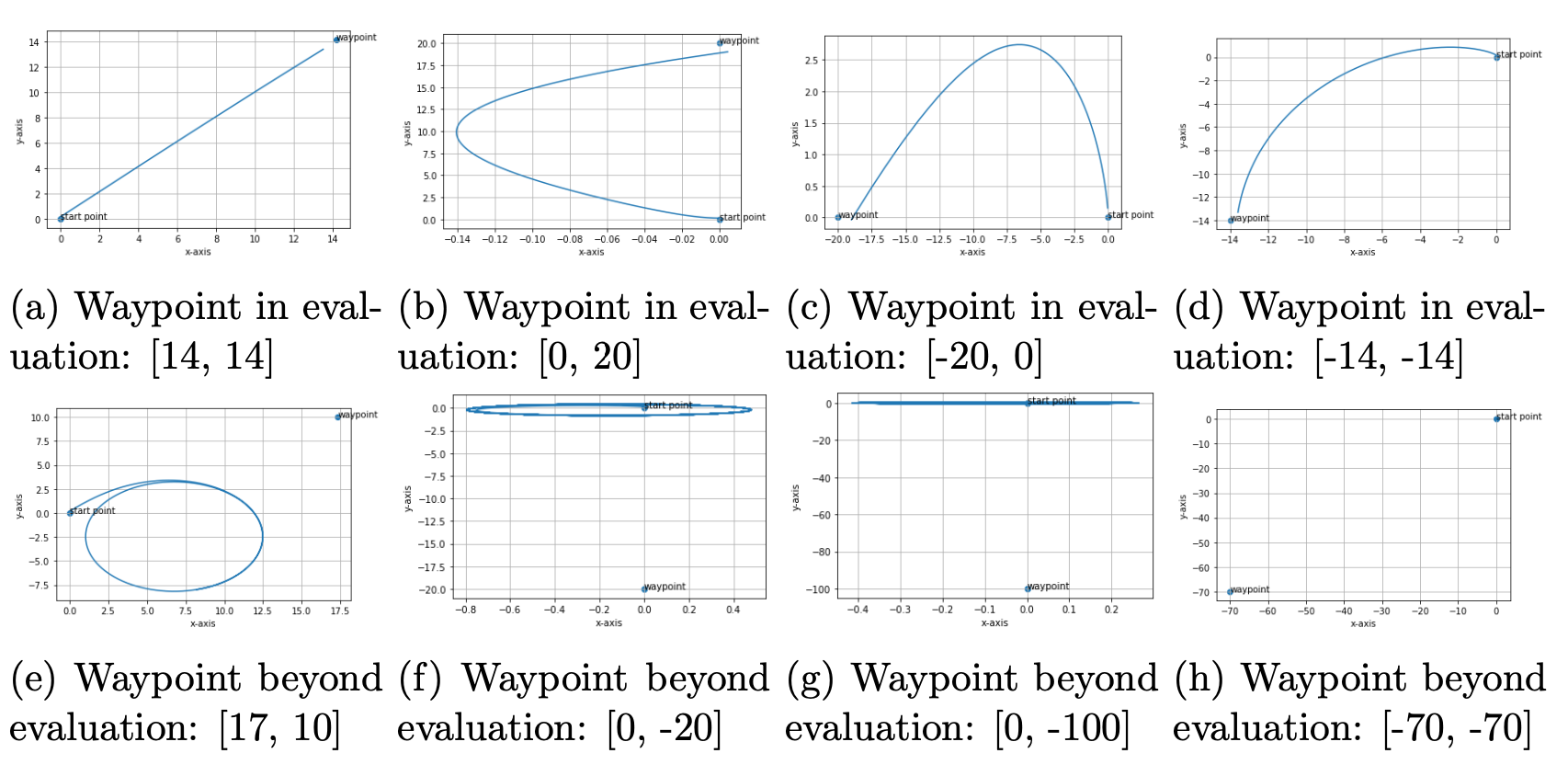
The results demonstrated that the controller derived from the evolutionary algorithm performed more sensibly than the one obtained through gradient descent. As shown in Figure 2, the controller worked well for the waypoints specified in the evaluation list, which were used to guide the evolutionary algorithm in selecting fit individuals. However, when presented with waypoints beyond the list, the controller failed to perform satisfactorily, indicating that its generalization capability was limited.